运营商大数据精准获客方式有哪些? 在我国大数据有着很高的利用率,从国家战略,到互联网企业创建自身应用的大数据体系,说明我国一直在建设和大力发展大数据战略,大数据应用方式也逐渐丰富和多样化,运营商大数据就是其中一个典型的例子。 技术文章 2021年07月14日 3 点赞 0 评论 1611 浏览
运营商如何利用大数据从网站、APP抓取信息实现精准获客 一直有很多人都有一个疑惑,为啥访问了没几日的网站或是app便会有人给打过电话来询问自身有关的内容。那大家的手机号码是通过什么技术手段或是什么方式获得到的呢? 技术文章 2021年07月08日 3 点赞 0 评论 2472 浏览
梦里寻他千百度,慕然回首,大数据却在灯火阑珊处 对于大部分人来说,大数据已经是一个比较熟悉的话题了,大家每天都或多或少会听到有人说起与大数据相关的话题。不可否认的是,随着互联网技术的发展,网络上的信息体量正在不断增加,数据信息化正离大家越来越近。 技术文章 2021年06月30日 0 点赞 0 评论 1360 浏览
大数据时代,要想掌握财富必须掌握数据 现在运营商大数据是除了BAT这些互联网巨头之外,少有的掌握了巨大的用户数据的商家,不论是中国移动、中国联通,还是中国电信,这些运营商掌握的用户数据都是以亿作为单位的,据不完全统计,三大运营商的用户总数已经超过了15亿左右,比中国总人口都多。 技术文章 2021年06月29日 0 点赞 0 评论 1413 浏览
数据采集软件开发可以为用户提供什么样的商业模式? 我们处在一个技术高度发达的时代,随着各类信息技术的不断发展,这就使得我们随时都在产生着各类数据信息,数据的总量也随之不断增加。这些数据可能来自于线上商品购物、也可能是对于资讯信息的浏览这一方面或者是对于视频平台的观看行为习惯等等。于是乎,想要走进用户,了解用户的需求,也需要一些数据信息。为此,也使得数据采集软件开发在现阶段逐渐流行火热起来。 技术文章 2021年06月25日 0 点赞 0 评论 1318 浏览
运营商大数据可以做些什么? 运营商大数据精准建模是通过对联通,移动,电信的用户数据进行分析和抓取的,根据其用户的网站,网址,网页的上网行为;手机APP的使用行为,注册行为;400电话,固话,座机的拨打,接听行为;短信的接收,发送,交互行为;关键词的搜索行为等综合行为数据,再通过运营商大数据建立数据模型对运营商的2G,3G,4G,5G用户数据的进行全面的分析筛选和抓取。 技术文章 2021年06月23日 1 点赞 0 评论 1301 浏览
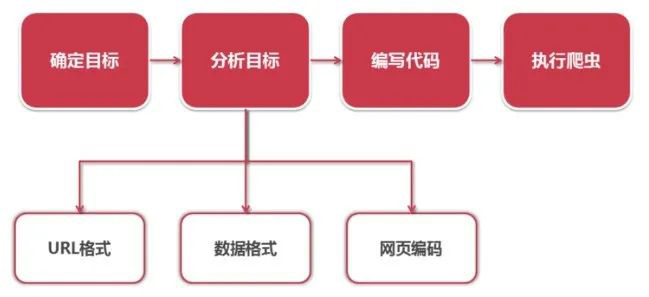
Python网页数据抓取实战 分析要抓取的url的格式,限定抓取范围。分析要抓取的数据的格式,本实例中就要分析标题和连接这两个数据所在的标签的格式。分析要抓取的页面编码的格式,在网页解析器部分,要指定网页编码,然后才能进行正确的解析。 技术文章 2021年06月22日 1 点赞 0 评论 1524 浏览
大数据常见安全问题解析 由于大数据分布式平台的特殊性,防火墙、病毒防治等常规安全保障机制没有办法确保大数据服务的安全,大数据在应用过程中往往存在如下一些安全问题。 技术文章 2021年06月21日 1 点赞 0 评论 1684 浏览
APP数据采集常见思路分享 抓取APP数据和抓取网页数据是不太一样的,抓取网页数据可以采用模拟访问网站然后抓取网页接收内容的模式进行数据抓取。而APP则更倾向于通过截获数据传输包的形式进行(Wireshark和Fiddler+Python)。APP数据采集的常见思路是怎样的呢?和天启IP一起来看看吧~ 技术文章 2021年06月18日 2 点赞 0 评论 1555 浏览
一篇文章让你了解大数据采集系统 大数据平台是指以处理海量数据存储、计算及不间断流数据实时计算等场景为主的一套基础设施。既可以采用开源平台,也可以采用华为、星环等商业级解决方案,既可以部署在私有云上,也可以部署在公有云上。 技术文章 2021年06月17日 0 点赞 0 评论 1232 浏览